

这里要了解LuaJIT的两种运行模式:JIT、Interpreter
Interpreter模式:那么没有JIT的时候怎么办呢?还有一个Interpreter模式。事实上这个模式跟原生Lua的原理是一样的,就是并不直接编译成机器码,而是编译成中间态的字节码(bytecode),然后每执行下一条字节码指令,都相当于switch到一个对应的function中执行,相比之下当然比JIT慢。但好处是这个模式不需要运行时生成可执行机器码(字节码是不需要申请可执行内存空间的),所以任何平台任何时候都能用,跟原生Lua一样。这个模式可以运行在任何LuaJIT已经支持的平台,而且你可以手动关闭JIT,强制运行在Interpreter模式下。
我们经常说的将Lua编译成bytecode可以防止破解,这个bytecode是Interpreter模式的bytecode,并不是JIT编译出的机器码(事实上还有一个在bytecode向机器码转换过程中的中间码SSA IR,有兴趣可以看LuaJIT官方WIKI),比较坑的是可供32位版本和64位版本执行的bytecode还不一样,这样才有了著名的2.0.x版本在iOS加密不能的坑。
二、JIT模式一定更快?不一定!
iOS不能用JIT,那么安卓下应该就可以飞起来用了吧?用脚本语言获得飞一般的性能,让我大红米也能对杠iPhone!然而,并不是安卓不能开启JIT,而是JIT的行为极其复杂,对平台高度依赖,导致它在以arm为主的安卓平台下,未必能发挥出在PC上的威力,要知道LuaJIT最初只是考虑PC平台的。
首先我们要知道,JIT到底怎么运作的。LuaJIT使用了一个很特殊的机制(也是其大坑),叫做trace compiler的方式,来将代码进行JIT编译的。什么意思呢?它不是简单的像C++编译器那样直接把整套代码翻译成机器码就完事了,因为这么做有三个问题:
-
编译时间长,这点比较好理解。
-
更关键的是,作为动态语言,难以优化。例如对于一个function foo(a),这个a到底是什么类型,并不知道,对这个a的任何操作,都要检查类型,然后根据类型做相应处理,哪怕就是一个简单的a+b都必须这样(a和b完全有可能是两个表,实现的__add元方法),实际上跟Interpreter模式就没什么区别了,根本起不到高效运行的作用;
-
很多动态类型无法提前知道类型信息,也就很难做链接(知道某个function的地址、知道某个成员变量的地址)。
那怎么办呢?这个解决方案可以另写一篇文章了。这里只是简单说一下LuaJIT采用的trace compiler方案:首先所有的Lua都会被编译成bytecode,在Interpreter模式下执行,当Interpreter发现某段代码经常被执行,比如for循环代码(是的,大部分性能瓶颈其实都跟循环有关),那么LuaJIT会开启一个记录模式,记录这段代码实际运行每一步的细节(比如里头的变量是什么类型,猜测是数值还是table)。有了这些信息,LuaJIT就可以做优化了:如果a+b发现就是两个数字相加,那就可以优化成数值相加;如果a.xxx就是访问a下面某个固定的字段,那就可以优化成固定的内存访问,不用再走表查询。最后就可以将这段经常执行的代码JIT化。
这里可以看到,第一,Interpreter模式是必须的,无论平台是否允许JIT,都必须先使用Interpreter执行;第二,并非所有代码都会JIT执行,仅仅是部分代码会这样,并且是运行过程中决定的。
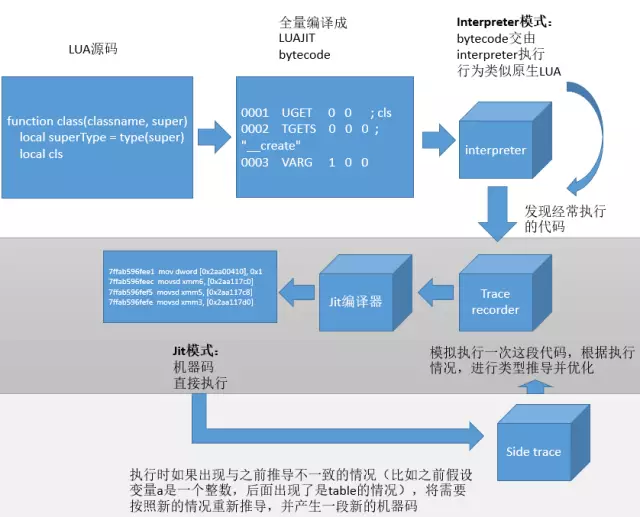
那么说了JIT怎么运作的,看起来没什么问题呀,为何说不一定更快呢?这里就有另一个大坑:LuaJIT无法保证所有代码都可以JIT化,并且这点只能在尝试编译的过程中才知道。
听起来好像没什么概念。事实上,这种情况的出现,有时是毁灭性的,可以让你的运行速度下降百倍。对,你没看错,是百倍,几ms的代码突然飙到几百ms。而JIT失败的原因非常多,而当你理解背后的原理后会知道,在安卓下JIT失败的可能要比PC上高得多。
根据我们在安卓下的使用来看,最常见的有以下几种,并且后面写上了应对方案。
3.1 可供代码执行的内存空间被耗尽->要么放弃JIT,要么修改LuaJIT的代码
要JIT,就要编译出机器码,放到特定的内存空间。但是arm有一个限制,就是跳转指令只能跳转前后32MB的空间,这导致了一个巨大的问题:LuaJIT生成的代码要保证在一个连续的64MB空间内,如果这个空间被其他东西占用了,LuaJIT就会分配不出用于jit的内存,而目前LuaJIT会疯狂重复尝试编译,最后导致性能处于瘫痪的状态。
虽然网上有一些不修改LuaJIT的方案(http://www.freelists.org/post/luajit/Performance-degraded-significantly-when-enabling-JIT,9),在Lua中调用LuaJIT的jit.opt的api尝试将内存空间分配给LuaJIT,但根据我们的测试,在Unity上这样做仍然无法保证所有机器上能够不出问题,因为这些方案的原理要抢在这些内存空间被用于其他用途前全部先分配给LuaJIT,但是uLua可以运行的时候已经是程序初始化非常后期的阶段,这个时候众多的Unity初始化流程可能早已耗光了这块内存空间。相反Cocos-2dx这个问题并不多见,因为LuaJIT运行早,有很大的机会提前抢占内存空间。
无论从代码看还是根据我们的测试以及LuaJIT maillist的反馈来看,这个问题早在2.0.x就存在,更换2.1.0依然无法解决,我们建议,如果项目想要使用jit模式,需要在android工程的Activity入口中就加载LuaJIT,做好内存分配,然后将这个luasate传递给Unity使用。如果不愿意趟这个麻烦,那可以根据项目实际测试的情况,考虑禁用jit模式(见文章第9点)。一般来说,Lua代码越少,遇到这个问题的可能性越低。
3.2 寄存器分配失败->减少local变量、避免过深的调用层次
很不幸的一点是,arm中可用的寄存器比x86少。LuaJIT为了速度,会尽可能用寄存器存储local变量,但是如果local变量太多,寄存器不够用,目前JIT的做法是:放弃治疗(有兴趣可以看看源码中asm_head_side函数的注释)。因此,我们能做的,只有按照官方优化指引说的,避免过多的local变量,或者通过do end来限制local变量的生命周期。
3.3 调用c函数的代码无法JIT->使用ffi,或者使用2.1.0beta2
这里要提醒一点,调用c#,本质也是调用c,所以只要调用c#导出,都是一样的。而这些代码是无法JIT化的,但是LuaJIT有一个利器,叫ffi,使用了ffi导出的c函数在调用的时候是可以JIT化的。
另外,2.1.0beta2开始正式引入了trace stitch,可以将调用c的lua代码独立起来,将其他可以jit的代码jit掉,不过根据作者的说法,这个优化效果依然有限。
3.4 JIT遇到不支持的字节码->少用for in pairs,少用字符串连接
有非常多bytecode或者内部库调用是无法JIT化的,最典型就是for in pairs,以及字符串连接符(2.1.0开始支持JIT)。
具体可以看http://wiki.luajit.org/NYI,只要不是标记yes或者2.1的代码,就不要过多使用。
完整的LuaJIT的exe版本都会带一个JIT目录,下面有大量LuaJIT的工具,其中有一个v.lua,这是LuaJIT Verbose Mode(另外还有一个很重要的叫p.lua,luajit profiler,后面会提到),可以追踪LuaJIT运行过程中的一些细节,其中就可以帮你追踪JIT失败的情况。

当你看到以下错误的时候,说明你遇到了JIT失败:
failed to allocate mcode memory,对应错误3.1
NYI: register coalescing too complex,对应错误3.2
NYI: C function,对应错误3.3(这个错误在2.1.0beta2中已经移除,因为有trace stitch)
NYI: bytecode,对应错误3.4
这在LuaJIT.exe下使用会很正常,但要在Unity下用上需要修改v.lua的代码,把所有out:write输出导向到Debug.Log里。




